I was deep into debugging a production issue on Monday evening — my app’s “Resend” service just wouldn’t respond. Logs looked fine, my deployment was clean, and nothing had changed in the codebase.
After 20 minutes of panic and console refreshing, I realized it wasn’t me.
AWS was down.
Suddenly it made sense — every microservice, every queue, every endpoint I depended on was tangled with AWS US-East-1. My stack hadn’t broken — the cloud had.
Where It Happened
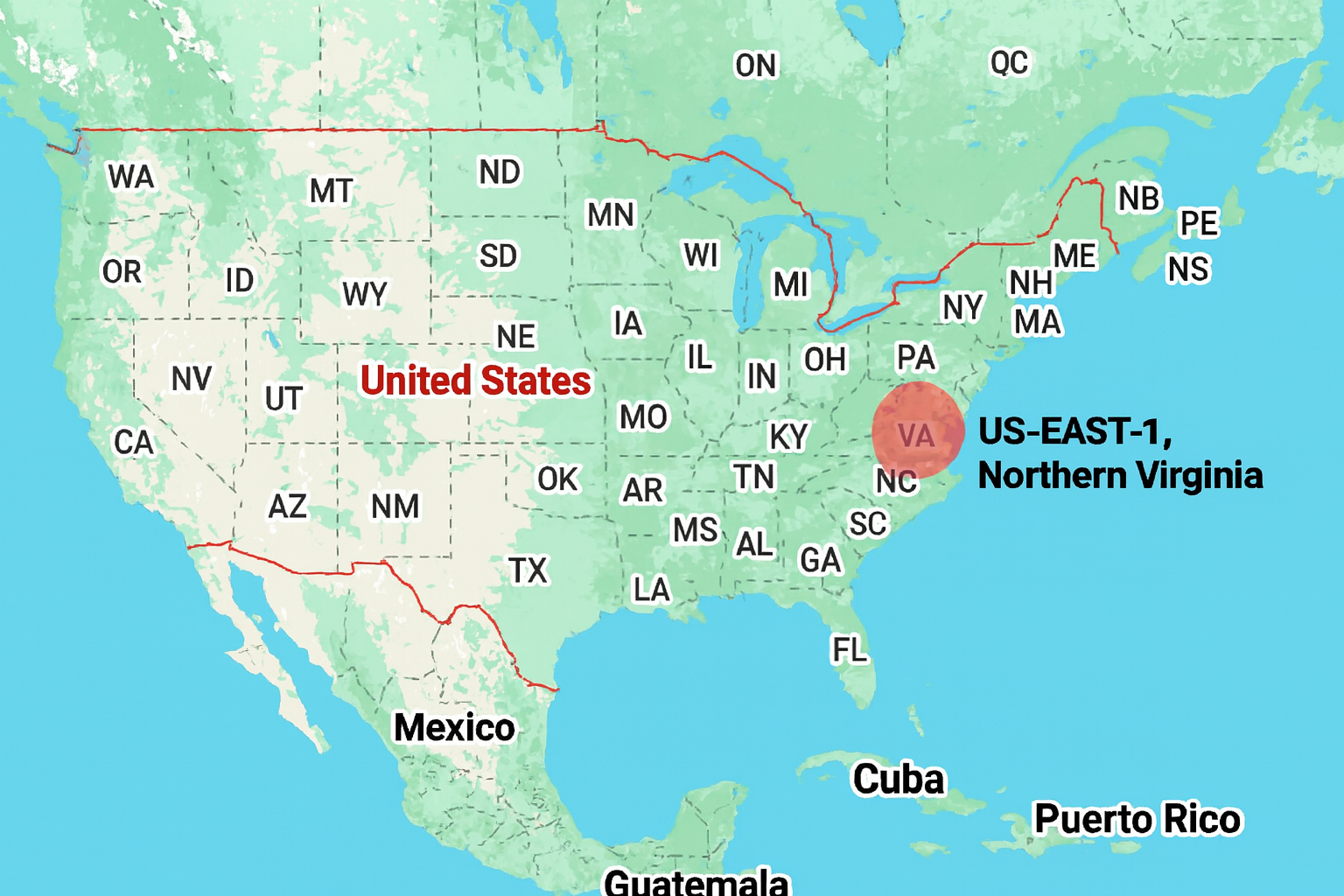
- The outage started in US-East-1, also known as Northern Virginia — one of AWS’s oldest and largest regions.
- If you’ve ever selected a region like “us-east-1” or “ap-south-1” while creating an AWS resource, you’ve used these zones.
- It hosts core AWS global services (like Route 53, IAM, CloudFront origins).Many internal and customer systems rely on it. It’s the default region for many setups — which means when this region goes down, half the internet feels it.
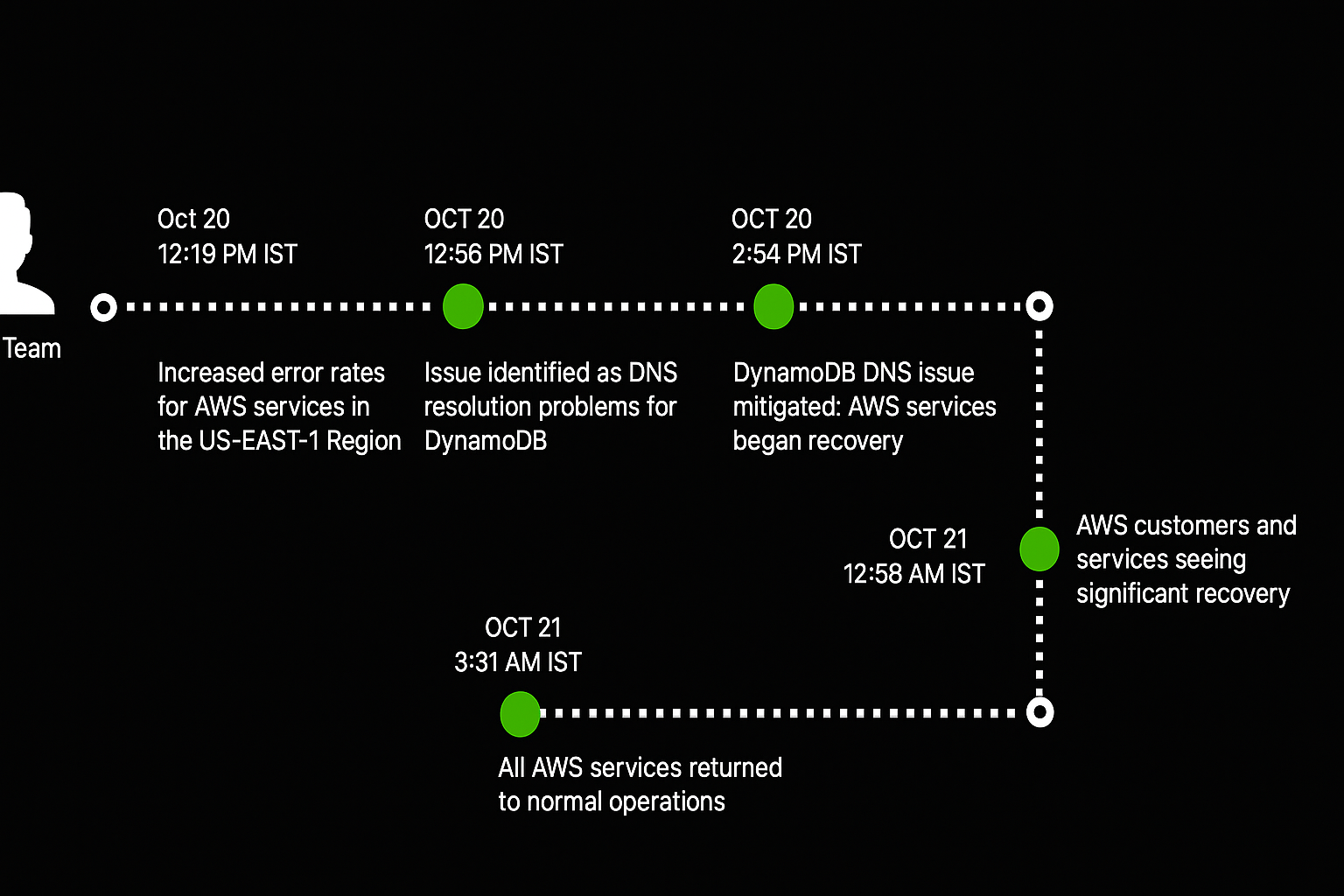
Here’s what went down (in IST time):
- 12:19 PM → AWS teams noticed increased error rates in the US-East-1 region via monitoring systems.
- 12:56 PM → They identified the root cause as a DNS resolution issue within DynamoDB.
- 12:56 PM – 3:15 AM → Teams worked to isolate and fix the issue; customers started seeing partial recovery around midnight.
- 3:31 AM → Full recovery confirmed — all services were back to normal.
That’s almost 15 hours of partial or complete disruption — affecting both AWS customers and Amazon’s own internal systems.
What Actually Broke — The DNS Chain Reaction
The root issue? DNS resolution failure inside DynamoDB.
Here’s what that means in simple terms 👇
Let’s say you’re running an app server (maybe on EC2 or outside AWS). To store or read data, your app connects to DynamoDB via an HTTP endpoint — something like: dynamodb.us-east-1.amazonaws.com
Behind the scenes, before your app can reach DynamoDB, it needs to resolve that domain name into an IP address.
That process — converting dynamodb.us-east-1.amazonaws.com → xx.xx.xx.xx — is called DNS resolution.
The DNS lookup is typically handled by Route 53, AWS’s own DNS service.
But when the DNS system itself fails (or returns incorrect responses), none of the dependent services can reach DynamoDB — which means:
- EC2 apps trying to read/write data fail.
- Lambda functions timeout.
- APIs depending on DynamoDB collapse.
In short, it caused a cascading failure across dependent services.
Why It Hit So Hard
Because so many services — directly or indirectly — rely on US-East-1 and DynamoDB, this wasn’t an isolated incident.
Even internal AWS components that depend on these systems were impacted.
That’s why everything from Alexa voice commands to Fortnite matchmaking and Amazon.com itself showed errors or slowed down.
Lessons for Developers
- Never depend on a single AWS region.
Always use multi-region failover or replication for critical services. - Add caching layers.
When databases go down, cached reads can keep your app partially functional. - Monitor DNS and upstream dependencies.
It’s easy to miss that DNS can be a single point of failure.
Conclusion
The AWS outage wasn’t just a technical failure — it was a reminder of how fragile the modern web really is.
One region, one DNS bug, and half the internet grinds to a halt.
So the next time your app goes down and you’re panicking in your logs — take a breath.
It might not be you.
It might just be AWS US-East-1 having a bad day.